

As enteprise networks grow larger and more complex, IT teams are increasingly dependent on the enhanced network visibility and monitoring capabilities provided by log analytics solutions.
Log analytics gives enterprise Engineering, DevOps, and SecOps teams the ability to efficiently troubleshoot cloud services and infrastructure, monitor the security posture of enterprise IT assets, and measure application performance throughout the application lifecycle or DevOps release pipeline.
For this week’s blog post, we’re bringing you our definitive guide to log analytics in 2023. You’ll learn why log analytics is becoming more important for enterprise organizations, what sort of information you can find in your log data, and the most important enterprise use cases for log analytics. We’ll also share some details about two familiar log analytics solutions that are available today: ELK stack and ChaosSearch.

What is Log Analytics?
Log analytics is an IT capability that allows Engineering, DevOps, and SecOps teams to aggregate, analyze, and visualize machine-generated log data from the applications, cloud services, endpoint devices, and network infrastructure that make up modern enterprise IT environments.
Log analytics empowers teams with enhanced network observability, allowing them to actively monitor the performance, operational status, and security posture of IT assets across the enterprise network.
What is Log Data?
Logs are the primary data source for enterprise log analytics. A log is a timestamped record of an event or transaction that occurs within an application, cloud service, endpoint device, operating system, or across a network.
When developers program a piece of networking equipment, an operating system, or a software application, a logging system is typically included as a means of recording events and transactions that take place within the system. As users interact with the system, logs are machine-generated to create a record of events and transactions that occurred during the user session.
As the logs are created, they are automatically written into a log file, often using a standardized protocol like the System Logging (Syslog) Protocol or a structured format such as the NCSA Common Log Format. These standards allow applications and network devices to generate logs in a structured format that can be easily parsed and normalized to support log analytics initiatives.
Log files contain different information depending on which protocol they use and the application or device that generated the log. Applications and cloud services generate event logs that can be used for auditing and troubleshooting.
Event logs include data such as:
- Version - A log that is written in a standardized format often includes information about which version of that standard is being used.
- Date - The date on which the log entry was generated.
- Timestamp - A timestamp can tell security analysts the exact time at which the log entry was generated. Log analytics software can analyze timestamped log data to identify and correlate events across applications and services in complex IT environments.
- Host Name - The name or IP address of the host machine or server where the log was generated.
- Application Name - The name of the application or service that generated the log.
- User Name - The name or IP address of the user who was logged into the host machine during the session when the log was generated.
- Structured Data - System metrics such as request processing time, number of packets sent/received, or service status code, stored in a structured data format.
- Event Type - Many event logging protocols include an identification number that specifies the event type. Event types can include things like policy changes, use of privileges, system events, object access, failed or successful login attempts, account management actions, failed or successful requests, and more.
- Message - Logs often include a short message describing the event that generated the log. Some logging protocols specify message levels that correspond to the severity of the event, ranging from debugging messages to informational messages, errors, alerts, and emergency messages that indicate system failure.
Log analytics solutions allow DevSecOps teams to aggregate log data from numerous applications and services in a centralized location, then build customized queries to efficiently extract insights from the data.
READ: How to Move Kubernetes Logs to S3 with Logstash
In addition to event logs, database applications often generate transaction logs that record changes in the database and support business continuity and disaster recovery use cases.
Web servers can be programmed to generate server logs that include information about user access patterns, resource consumption, packet exchange, and other metrics.
How Does Log Analytics Work?
Log analytics software tools allow Engineering, DevOps, and SecOps teams to query and analyze log data from throughout the enterprise network.
Generation and Aggregation
Log data is automatically generated by applications, services, and infrastructure that compromise the enterprise network. Before the log data can be analyzed, it needs to be aggregated in a centralized log management platform. Log analytics software solutions allow teams to automate the process of aggregating log files from throughout the enterprise IT environment.
Parsing and Normalization
Log parsing is the process of transforming log data into a structured format for storage and downstream analysis. Data normalization is a process where log data from multiple sources is integrated into a single source with a single format. Normalization should remove redundancies and duplicate data while ensuring that related data is stored together. Parsing and normalization are necessary steps to preparing raw log data for analytics applications.
Storage and Indexing
Once log data has been aggregated and normalized, the next step is to index the data. Data indexing is a process of reorganizing the normalized log data into a representation that minimizes its storage footprint and increases the efficiency and speed with which it can be queried.
LEARN How the Chaos Index® Activates Your Data Lake for Search & Analytics at Scale
Querying and Analysis
Indexed log data can be queried and analyzed to drive insights into application performance, network security, or the operational status of cloud services. Modern log analytics software allows IT agents to query their log data by writing customized relational, text search, or machine learning queries.
Querying and analyzing log data can help developers or SecOps teams diagnose and debug application performance issues, identify and remediate network security threats, or measure the health and functionality of cloud services.
Visualization and Dashboarding
Data visualizations make it easy for human users to consume, understand, and make business-decisions using their log data. Log analytics software includes the visualization and dashboarding capabilities that IT agents need to make sense of their log data.

Three Use Cases for Log Analytics
During the late 1990s and early 2000s, organizations experienced a software revolution that was characterized by widespread accelerated adoption of software applications to support core business processes. The software revolution increased the complexity of enterprise IT environments and added significantly to the overall volume of log data generated by modern organizations.
Today, enterprise organizations are generating and analyzing more log data than ever before. Here are three ways log data is being used to support IT processes and enhance business outcomes.
Security Operations and Threat Hunting
Monitoring the security posture of enterprise networks with security log analysis is critical for responding to digital threats and preventing data breaches.
Enterprises may rely on Security Information and Event Management (SIEM) or network observability platforms for real-time alerting on security events. Log analytics can extend those security operations and threat hunting capabilities by facilitating use cases like long-term threat detection and root cause or forensic analysis.
READ: Log Analytics and SIEM for Enterprise Security Operations and Threat Hunting
Application Troubleshooting and DevOps Efficiency
DevOps engineers use log analytics to collect feedback on application performance as new updates and releases make their way through the code development pipeline and into the production environment.
An Application Performance Management (APM) tool may be used to instrument the application with software agents that collect logs, metrics and traces for analysis, but centralized log management is still useful for cost-effectively querying historical log data to understand long-term trends in application performance.
Log analytics allows DevOps teams to efficiently discover and debug errors as they strive to push higher-quality releases into production with greater frequency.
READ: Log Management and APM for Application Troubleshooting and DevOps Efficiency
Troubleshooting Cloud Services and Infrastructure
Enterprise IT teams can use log analytics to analyze logs from cloud services, driving insights into cloud service availability and performance, latency issues, resource allocation, security and configuration status, access history, and other factors.
Some of the most popular cloud services generate log data in their own unique formats, such as VPC Flow Logs, which capture IP traffic data from network interfaces, or ELB logs that capture requests sent to your AWS application load balancer.
READ: Troubleshooting Cloud Services and Infrastructure with Log Analytics
Log Analytics Tools and Technology in 2023
Enterprise organizations in 2023 are increasingly dependent on log analytics solutions to support use cases that range from application performance management to cybersecurity. These solutions range from the popular, open source ELK stack to innovative software-as-a-service (SaaS) products like ChaosSearch.
ELK Stack
One of the most widely used log analytics platforms is the open source ELK stack. This stack consists of three software tools that combine to deliver enterprise log analytics capabilities:
- Elasticsearch is an open source analysis engine that allows teams to index their log data in Lucene databases and query it using full-text search.
- Logstash is a log aggregator utility that allows teams to aggregate and centralize logs from a variety of sources into a Lucene database where it can be normalized and indexed prior to analysis.
- Kibana is a visualization and dashboarding tool that allows teams to create visual representations of their log data for easier consumption and to support business decision-making.
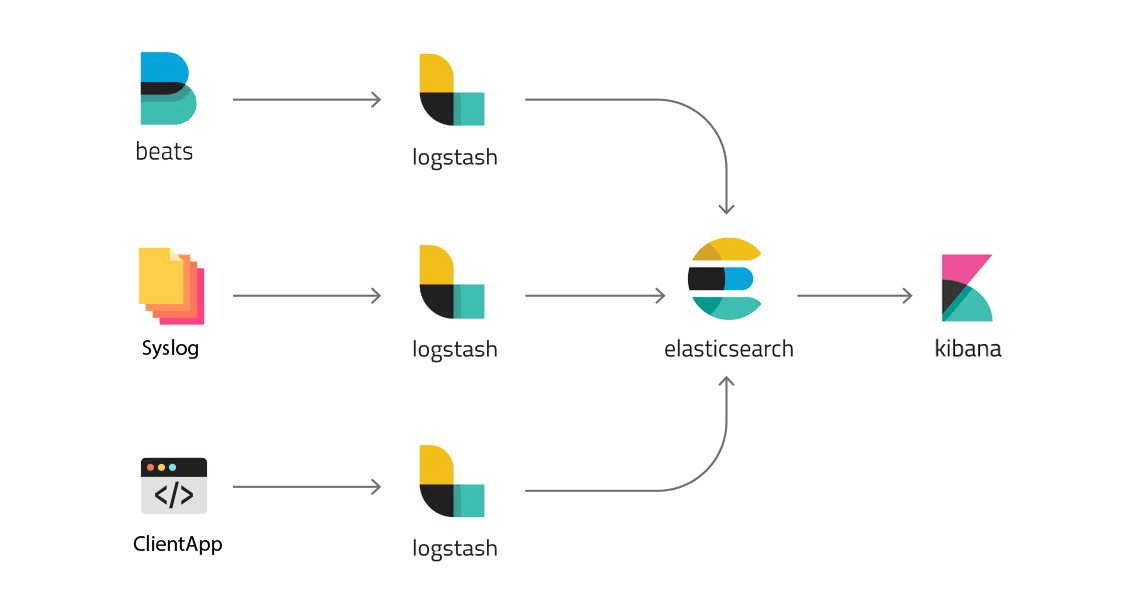
Image Source: Hacker Noon
While the ELK stack continues to enjoy widespread use, it does have its limitations when it comes to analyzing log data. As log data volumes and daily ingest grow in large organizations, these indices become extremely large. This leads to log analytics performance degradation that forces trade-offs between query performance, management complexity, and data retention.
READ: Let’s Talk about the ELK in the Room
ChaosSearch
The ChaosSearch Cloud Data Platform activates the data lake for analytics; it indexes customers’ cloud data, rendering it fully searchable and enabling analytics at scale with massive reductions of time, cost and complexity.
ChaosSearch is increasingly being adopted by organizations looking to replace the Elasticsearch stack. With ChaosSearch, customers can perform scalable log analytics on AWS S3 or GCS, using the familiar Elasticsearch API for queries, and Kibana for log analytics and visualizations, while reducing costs and improving analytical capabilities.
The platform consists of three proprietary technologies working together: Chaos Refinery®, Chaos Index®, and Chaos Fabric®.
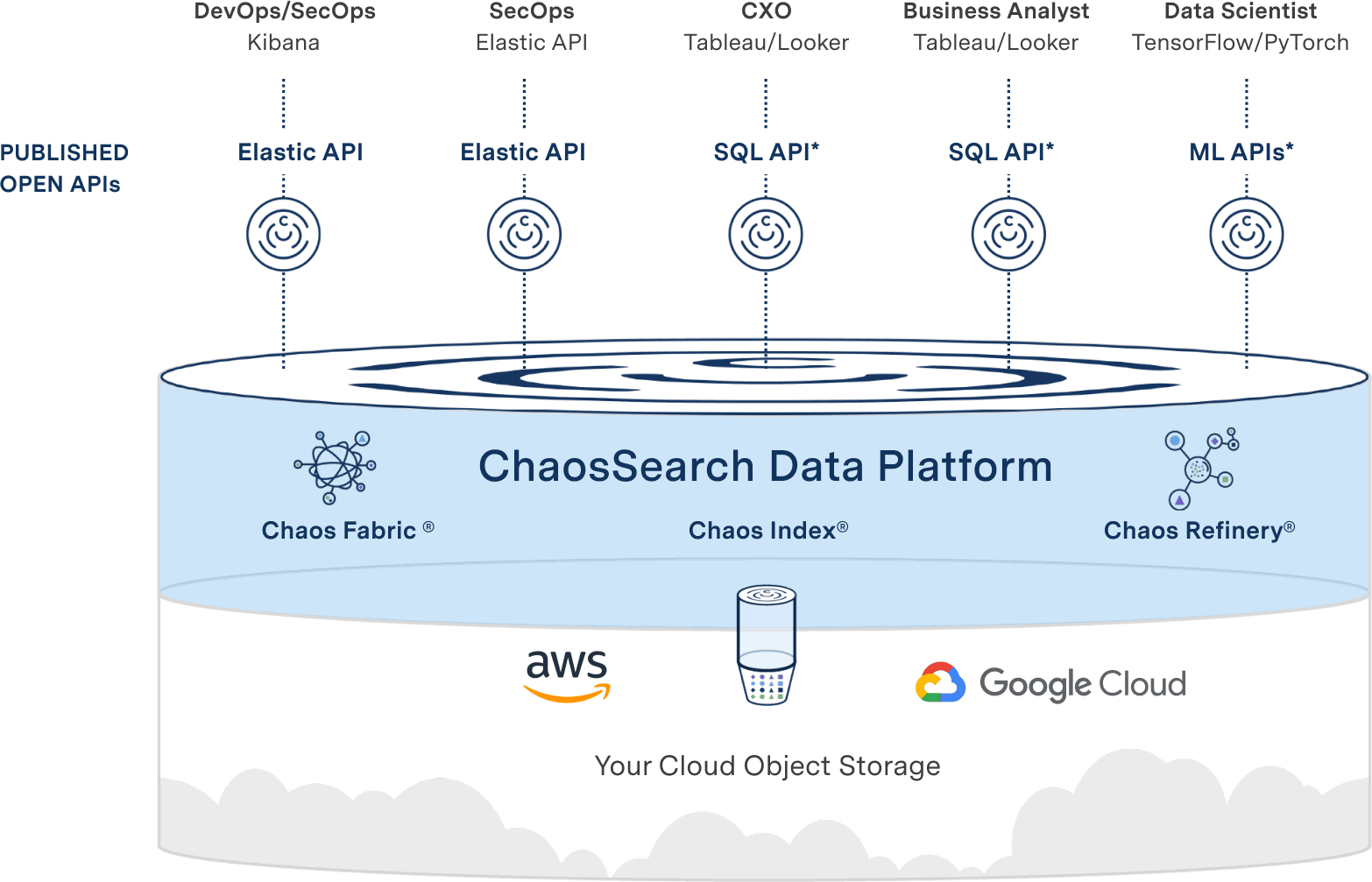
Image Source: ChaosSearch
Caption: ChaosSearch Cloud Data Platform for Log Analytics at Scale
Chaos Refinery enables IT and DevSecOps teams to virtually clean, prepare, and transform log data stored in Amazon S3 buckets with no data movement and no ETL process.
Log data is indexed with Chaos Index, a proprietary data storage format that compresses the data to decrease its storage footprint and enhance query performance. Cost-effective public cloud storage combined with the compression of Chaos Index means that organizations can retain log data for extended periods of time, enabling log data use cases like forensic auditing, root cause assessment, and long-term trend analysis.
Finally, Chaos Fabric offers containerized orchestration of ChaosSearch functions that include transforming, indexing, or querying data.
ChaosSearch allows teams to query their log data using relational (SQL) or non-relational (full-text search), with support for machine learning queries coming in 2022. These features will make ChaosSearch the first log analytics platform to offer true multi-dimensional data access and querying capabilities.
Getting Started with Log Analytics
As enterprise IT environments continue to grow in size and complexity, log analytics will continue to play a front-and-center role when it comes to monitoring cloud services, assessing application performance, and safeguarding network security.
Log analytics software solutions work by collecting and aggregating log data, parsing and normalizing the data to prepare it for processing, and indexing the data to make it more searchable. Once log data is indexed, teams can create customized queries to extract insights from their log data and drive business decision-making.
The ELK stack is one of the most popular log analytics solutions available to enterprises today, but as log data volumes grow and efficiency declines, it may make sense to migrate to an Elasticsearch replacement like ChaosSearch that delivers cost-effective log analytics capabilities with no data movement and no data retention trade-offs.

Related Content
- Read the blog: How Log Analytics Power Cloud Operations Use Cases
- Read the solution brief: ChaosSearch as a Replacement for Elasticsearch
- Read the Eckerson Group whitepaper: Can CloudOps Be Both Stable and Agile?

