


Build a Security Data Lake
Centralize logs with unlimited hot data retention to investigate advanced persistent threats and meet compliance requirements.


Reduce SIEM costs and improve visibility
Compliment existing threat detection and incident management systems like a SIEM, SOAR or XDR—while reducing the cost of security investigations at scale. Keep access logs in your existing security solution for real-time threat detection, and centralize all logs in ChaosSearch for full visibility at a fraction of the cost.

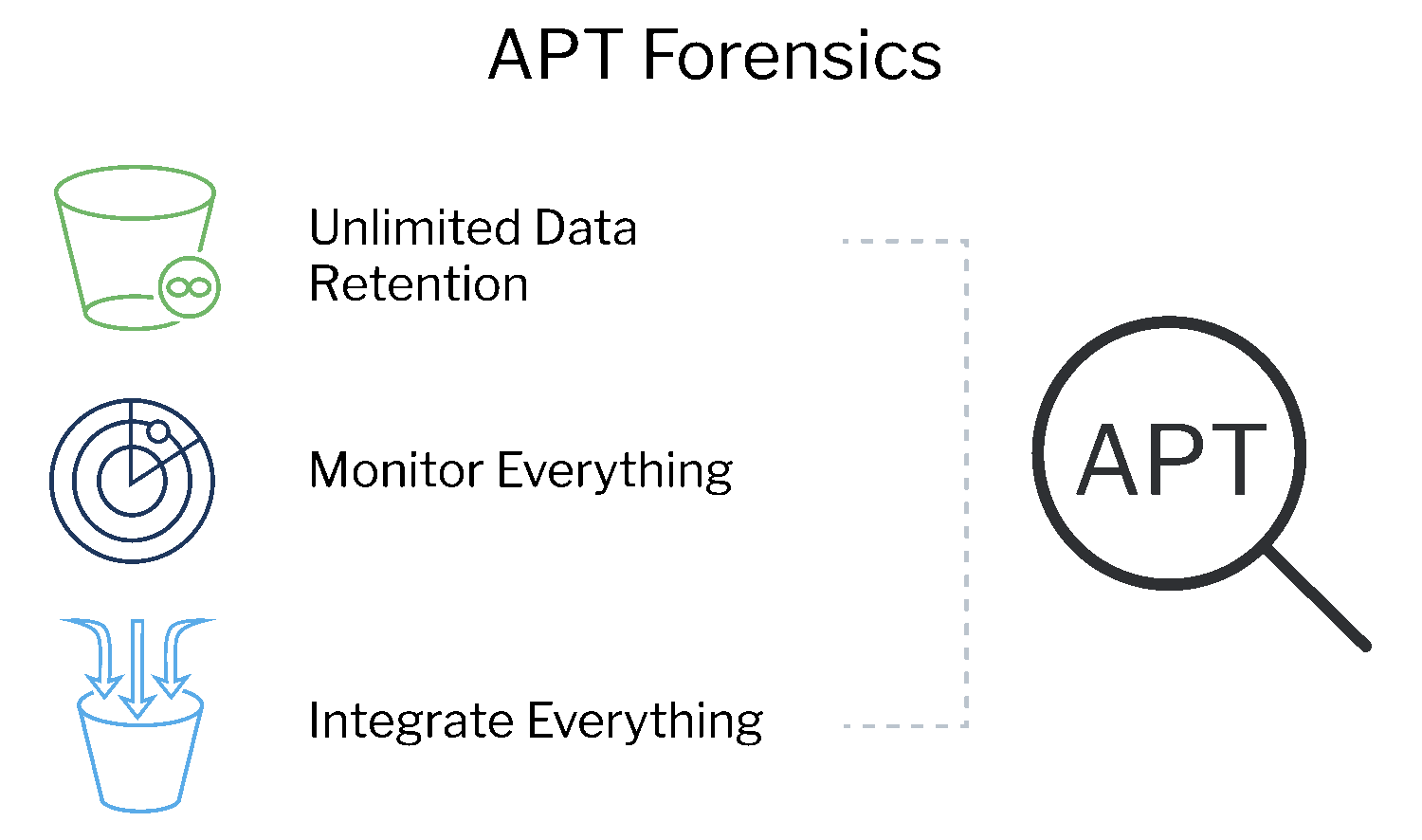
Retain unlimited data to investigate advanced persistent threats (APT)
Unlimited hot data retention allows SecOps teams to quickly analyze years of data and gain full visibility into traffic to face advanced persistent threats (APTs). Meet years-long compliance requirements without breaking the bank.


Trust an Amazon Security Lake Partner
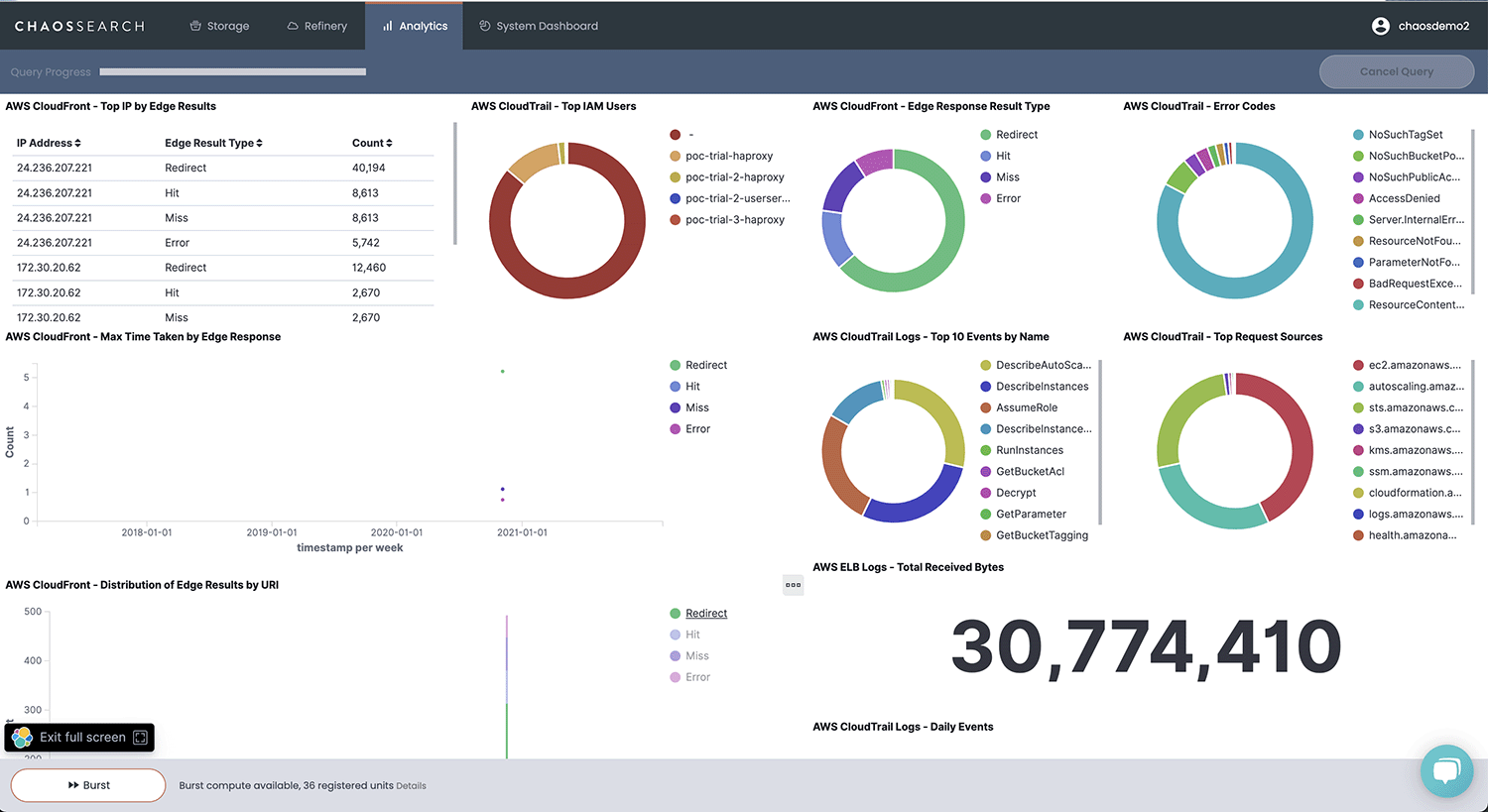
Analyze your Amazon Security Lake data alongside other logs via OpenSearch Dashboards or SQL at a fraction of the cost of alternatives to proactively detect vulnerabilities and face complex threats.


Made for cloud scale and complexity
Centralize logs across sources and analyze complex security threats at scale — without the costs of a SIEM or a Lakehouse. Get the ingest flexibility and hunting efficiency of a SIEM, with unlimited retention and a consumption-based pricing model. Only pay for the compute you use.


Created for a proactive security posture
Unlimited hot retention across all log data empowers SecOps teams to proactively look for potential issues before they happen, and quickly resolve them if they do.
- Monitor all access logs across applications and systems
- Identify suspicious processes and create process maps to identify root cause
- Monitor all IPs, ports, and endpoints that access the organization's systems
- Monitor inbound traffic sources and patterns

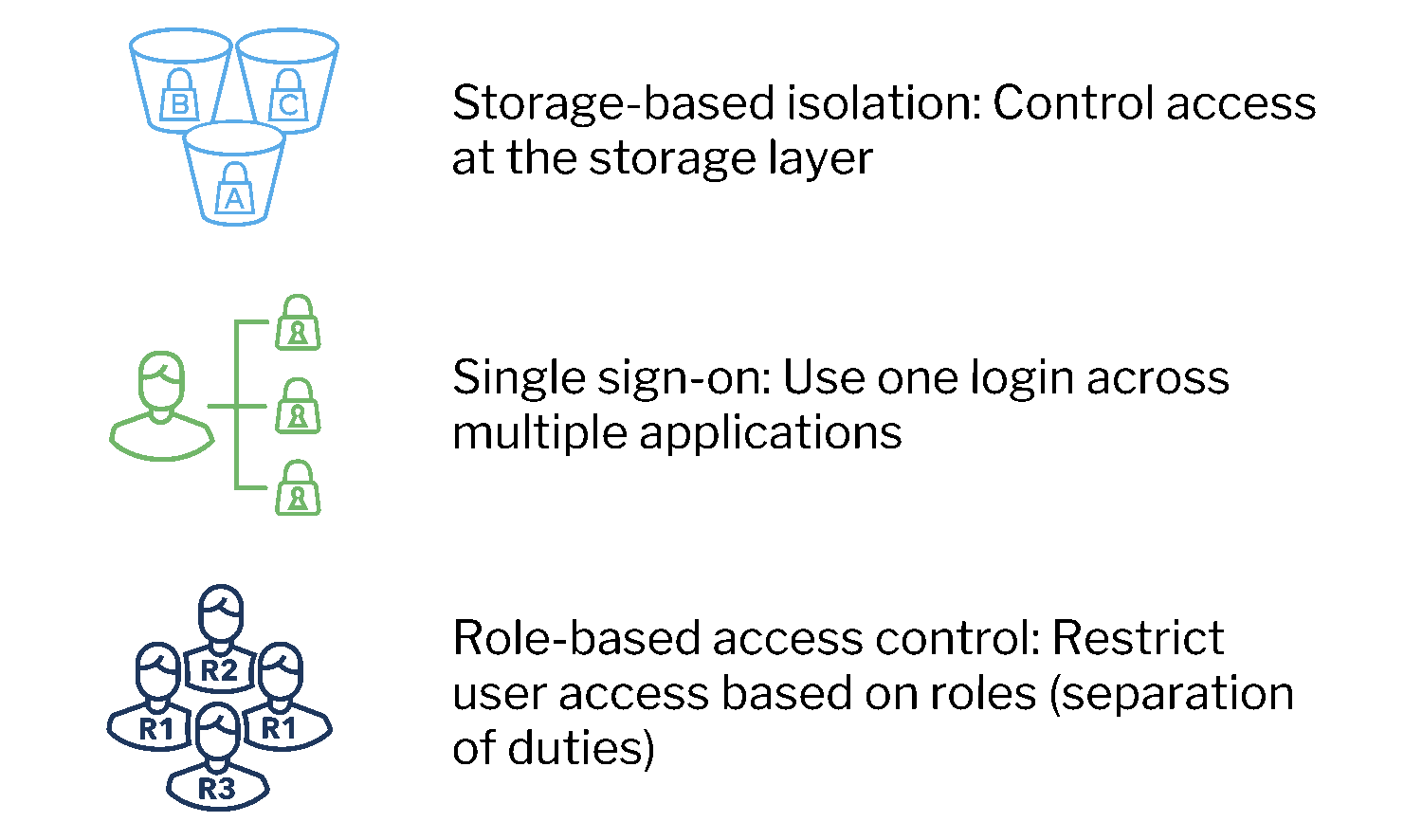
Built with security-first principles to meet compliance needs
Our security-first architecture allows security teams to keep ownership of data and frictionlessly manage access through SSO to meet SOC2, GDPR and HIPAA requirements. Unlimited hot data retention enables teams to seamlessly meet stringent compliance requirements.


Future-Proof Your Analytics at Scale
