

Jim Barksdale, former CEO of Netscape, once said “If we have data, let’s look at data. If all we have are opinions, let’s go with mine.” While Jim may have said this in jest, the exponential boom in data collection indicates that we increasingly prefer to rely on facts rather than conjecture when making business decisions. More data yields greater insights about customer preferences and experiences, internal processes, and security vulnerabilities — just to name a few. Shining light on dark data also generates opportunities for us to gain competitive advantages.
With so much to gain from the mastery of broad and deep data analysis, you might think that companies would analyze and scrutinize most if not all data from every angle. Except – they don’t. As it turns out, up to 73% of stored company data is never analyzed.
Why Data Stays in the Dark
Data that is stored, but never looked at, is known as “dark data”. Gartner, who coined the term, defines dark data as the information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes. So what kind of data goes unanalyzed that we could gain insight from – and just as important, how can we get at it?
Let’s take a closer look.
A lot of dark data exists because of industry standards or compliance requirements. Here are a few examples:
- Detailed historical financial records
- Old personnel records
- Raw survey data that has been mined for quick insights
Other data that commonly goes untouched is unstructured data, including
- Most log and event data
- Video surveillance recordings
- Customer call recordings.
In other words, if you MIGHT need the data, but don’t typically require it to make business decisions, it goes into deep storage and becomes dark data. Though you may not be leveraging it now, if analyzed, this data could deliver tremendous business value; the data you’ve been saving by default could provide insight that yields an incredible competitive advantage.
The Scoop on Data Storage “Temperature”
Not all storage space is created equally. In the world of big data, data storage is commonly spoken of in terms of relative temperature – and only data that is in “hot” storage is easily accessible: able to be analyzed and manipulated instantly. This convenience comes at a price, however, and the high expense of hot data storage makes maintaining and analyzing higher volumes of data here cost-prohibitive. On the other end of the spectrum, data in “cold” storage can contain much more history – but several barriers stand in the way to accessing data stored here.
As alluded to above, leaving data in a data store that is readily analyzed and manipulated comes at a hefty cost. For example, Amazon’s “hot” storage, Amazon EBS General Purpose SSD, currently costs $0.10 per GB-month of provisioned storage. This results in an astronomical cost for larger companies who generate multiple terabytes per day. Because of this, many companies rely on cold storage like Amazon AWS S3, which starts at roughly 20% of the cost of EBS.
Moving Big Data Takes Time and Money
So why not just move data from cold to hot storage when you need to analyze it? This is how data analysts have tackled the storage cost vs. analytics needs issue in the past. The process of moving data from cold storage to hot storage is known as ETL, which stands for Extract, Transform, and Load. It requires data to be identified in cold storage, reconfigured to match the schema, and uploaded into hot storage for analysis. This responsibility — preparing and moving data to make it accessible — is of critical importance in traditional solutions. It is also complex, and error prone. What’s more, it takes up to a whopping 80% of a data scientist’s job. When you consider that the average salary of a mid-level data scientist in the US is over $120,000, that’s a big chunk of change before analysis even starts. Further, once the data is moved — you’re on the clock for hot data storage costs as well.
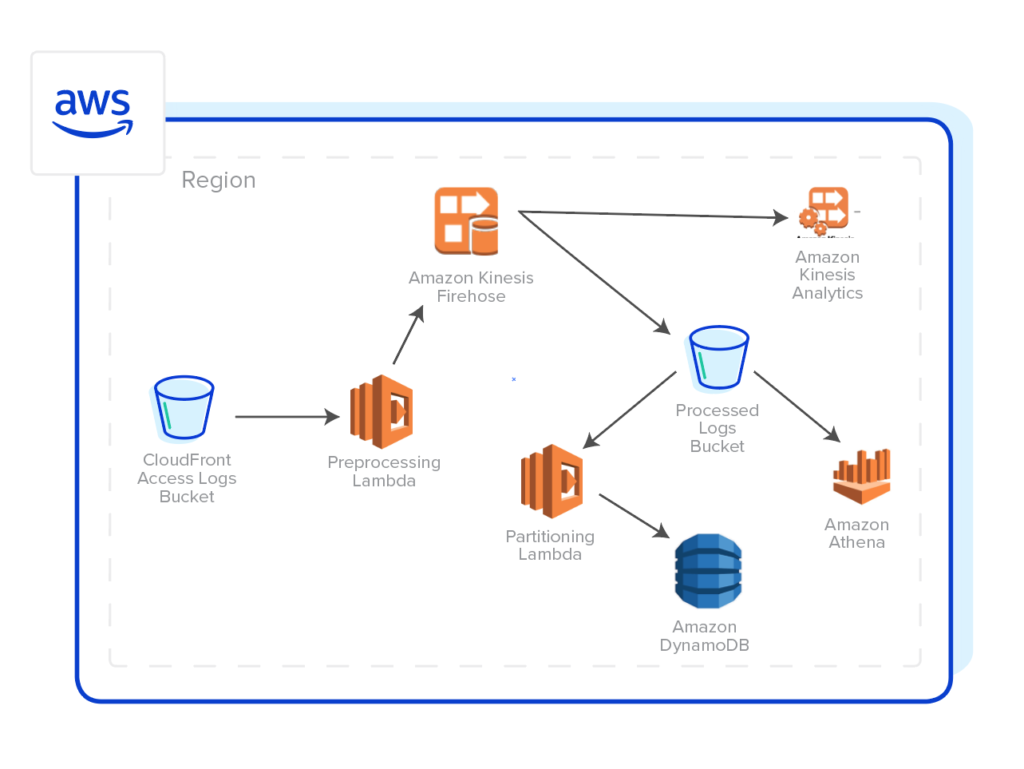
Considering the cost, complexity, and the other limiting factors associated with data movement, it’s easy to see why the majority of company data that is not immediately pertinent to operations remains untouched. It seems like a lot of work and money to simply access the data you have generated. So this begs the question: is there a way around it? Is there a simpler way to access and analyze the data without the hassle and exorbitant cost of ETL?
CHAOSSEARCH Sheds Light on Dark Data
At CHAOSSEARCH, we’ve created an innovative solution allowing you to access, manipulate, and analyze ALL of your data stored on Amazon AWS S3 without leaving the S3 environment — no ETL required. As you know, dark data exists largely because the cost and time required to access it makes audits of this type a low-priority task. CHAOSSEARCH disrupts the data storage and analytics market by eliminating the need for costly and complicated multi-tiered solutions like the ELK stack — giving you direct access to the data you own with no lag time.
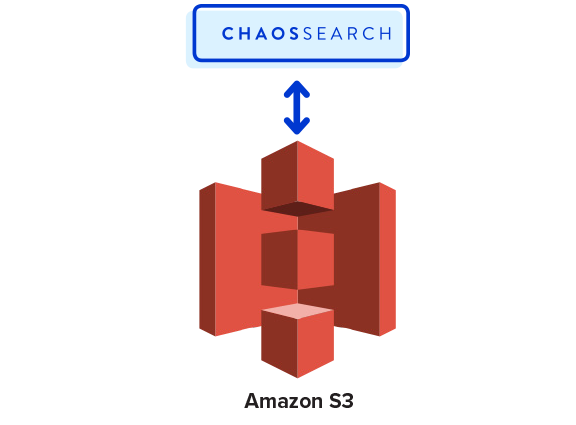
In addition to the time and expense saved by eliminating ETL, CHAOSSEARCH optimizes the use of Amazon S3’s already low storage cost with our patent-pending Data Edge index technology. In traditional solutions, data is indexed and reindexed as needed. These indexes are then stored with your data, significantly bloating your overall data usage. In contrast, the CHAOSSEARCH Data Edge index compresses data so that it takes up a fraction of the space that traditional solutions use. For example, CHAOSSEARCH indexing is 25x smaller and 60x faster to build than Elasticsearch. Because of this, there are no limits to the breadth or depth of data you can access at any given point in time. Query whatever you want, whenever you want — dark data included!

Finally, and perhaps best of all, by separating compute from storage, we are able to offer CHAOSSEARCH for less than half the cost of traditional solutions. When you’ve opened up all collected data for access, your only limitation is your imagination.
Ready to bring your dark data into the light? Sign up for our Free Trial and see for yourself how easy it is to mine months or even years of data.

