

Effective and efficient lakehouse data retention strategies are essential for enabling enterprise security operations (SecOps) teams to unlock the full value of your security log data.
As threats against enterprise IT assets and data grow in complexity, retaining security log data for extended periods of time (6-12 months or more) can activate valuable long-term security use cases like advanced persistent threat (APT) detection, security incident root cause analysis, incident response correlation, and more.
However, long-term security data retention at scale requires careful planning and the right approach to streamline data ingestion, ensure data availability and accessibility, control costs, and avoid transforming your data lakehouse into a data swamp.
In this blog, we’re taking a closer look at five lakehouse data retention tips that can enable long-term security use cases and help SecOps teams detect and investigate digital threats against your organization.

"Maligne Lake in Jasper National Park (Alberta, Canada)" by @CarShowShooter is licensed under CC BY-NC-SA 2.0.
3 Security Challenges in the Modern Data Lakehouse
A data lakehouse is a data management system that combines the storage characteristics of a data lake (e.g. easy data ingest, cost-effective data storage at scale, etc.) with the built-in analytical capabilities of a data warehouse (e.g. data governance, ACID transactions, etc.).

Comparison between data warehouse, data lake, and data lakehouse architectures.
With a data lakehouse platform like Databricks, organizations can centralize security data from throughout their IT infrastructure in a single location, then analyze the data in various ways to support cybersecurity use cases. But despite the benefits of centralized data storage and governance, organizations still face certain challenges and limitations around using the data lakehouse for security log and event analytics:
1. Diverse Security Data Formats
IT systems write security logs in a variety of different formats, including structured, semi-structured, and unstructured log formats. This creates a challenge for organizations that need to parse, tabulate, and query their security logs for analytical purposes.
Organizations running the Databricks Lakehouse platform can use Databricks Photon to run SQL queries on structured logs, but will need to find an alternative solution to help with parsing and querying semi-structured and unstructured logs.
2. Lakehouse Data Ingestion Challenges
Most organizations build and maintain Extract-Transform-Load (ETL) pipelines to ingest security data from source systems into the data lakehouse. But as the scale of security data and the number of sources increases, building and maintaining those ETL pipelines becomes increasingly costly, time-consuming, and complex.
Managing data pipelines also requires highly skilled personnel whose time is better spent developing new products and services than managing ETL infrastructure.
3. Lakehouse Data Retention Challenges
Without the right database solution and analytics tooling in place, retaining large amounts of security data over time can result in high data storage costs and/or poor query performance that makes it difficult for SecOps teams to get value from the data.
Data retention policy, organization, governance, and policy enforcement are also crucial when it comes to ensuring data quality and availability for security analytics while preventing the data lakehouse from degenerating into a data swamp.
Why is Lakehouse Data Retention Important for Security Use Cases?
Retaining security logs in your data lakehouse for extended periods of time can enable a variety of SecOps use cases that require analytical access to historical security data. These use cases include:
- Root Cause Analysis of Security Incidents - Long-term security data retention allows SecOps teams to conduct deeper investigations into security incidents. By reviewing historical log data, security teams can reconstruct the sequence of events that led to an incident and implement strategies to remediate any successfully exploited vulnerabilities.
- Detecting Advanced Persistent Threats - APTs are complex threats that can take months or years to develop inside a network.

An APT is a cyber attack that establishes a long-term presence inside the target network. Analytical access to historical security data helps security teams detect APTs.
Long-term log retention and historical log analysis can help organizations correlate security logs, alerts, and activity from disparate systems to detect APTs before they cause more damage.
- User Behavior Analytics (UBA) - Organizations can leverage UBA to detect anomalous user behavior patterns that could indicate an insider threat or a compromised user account. Historical user behavior data can be used to establish a baseline for normal user behavior, making it easier to detect suspicious or anomalous user activity.
- Incident Response Correlation - Long-term data retention gives SecOps teams the ability to correlate data from multiple sources as part of the incident response process. Correlative analysis can help SecOps teams identify unfolding cyber incidents and efficiently assess their impact.
- Insider Threat Detection - Insider threats often develop gradually, with behavior patterns slowly shifting over time as the employee becomes more daring and ambitious. Retaining security log data for the long term can help SecOps teams detect subtle changes in user behavior that unfold over time and could indicate an emerging Insider Threat against the organization.
Now let’s take a look at five lakehouse data retention tips to enable security use cases in your data lakehouse.
5 Lakehouse Data Retention Tips to Enable Security Use Cases
1. Streamline Data Ingestion with a Schema-on-Read Approach
Organizations that want to retain security log data in a data lakehouse might handle data ingestion by deploying data engineers to build ETL pipelines that extract security log data from source applications, apply schema to the logs via transformations, then load the log data into the data lakehouse. This reflects a schema-on-write approach, where a defined schema is applied to the data before it is written into the database.
While there are some advantages to ETL pipelines and schema-on-write, the major drawback is the time, cost, and complexity associated with managing ETL pipelines at scale. Instead, organizations that need to ingest large amounts of security log data from complex IT environments are better served by a schema-on-read approach where raw data can be quickly ingested in its source format and schema can be defined dynamically at query-time instead of during a resource-intensive ETL process.
A schema-on-read approach significantly decreases the up-front cost, time, and complexity of ingesting security log data into the data lakehouse.
2. Centralize Data Storage & Optimize Costs
Data centralization is one of the core value propositions of the data lakehouse model, but it’s also vital for enabling some of your most pressing security use cases.
Consolidating large amounts of security data in a unified security data lake ensures seamless access to historical data and enables use cases like root cause analysis, insider threat hunting, and compliance reporting. But retaining large volumes of security data for extended periods of time can be excessively expensive without the right strategies in place for optimizing and controlling costs.
Organizations can optimize data lakehouse architecture and reduce storage costs by:
- Leveraging cloud object storage from hyperscale providers as a data lakehouse storage backing to get the lowest possible data storage costs.
- Using data compression to reduce the size of data in storage without loss of fidelity.
- Storing data in cost-efficient formats like Delta Lake.
3. Unify Data Governance
Data governance is a set of practices that support two overarching goals:
- Ensuring the data quality, integrity, and accuracy in your lakehouse to support enterprise cybersecurity use cases.
- Ensuring the data security and privacy in your lakehouse to protect against external cyberthreats, mitigate insider threats, and support compliance with data privacy/security regulations.

Data governance encompasses a range of capabilities that help ensure the quality, availability, and security of data in the lakehouse.
Centralizing your security logs in a data lakehouse allows you to implement a single unified data governance framework that enforces consistent data management/governance policies across all of your data assets, regardless of their origin or structure. This includes policies like:
- Role-based Access Control (RBAC) policies that regulate data access based on the user’s job role and responsibilities.
- Data Versioning policies that track changes to data over time, allowing lakehouse administrators or compliance teams to audit changes or recover historical data.
- Data Masking policies that hide personally identifying information in log data from users who don’t need to see it.
- Data lineage systems that track the movement of data throughout its life cycle.
Databricks users can implement a unified governance approach with help from Unity Catalog, a unified data governance solution for the Databricks platform that delivers centralized data discovery, access control, lineage, and auditing capabilities.
4. Avoid Data Storage Cost/Availability Trade-offs
Organizations that retain security data at scale inside a data lakehouse will always face the temptation of imposing data retention windows or tiered data storage as a means of reducing storage costs.
For example, Databricks users have the option of storing data in three different storage tiers based on how frequently the data is accessed:
- Data in hot storage can be readily queried to support security use cases, but also comes with the highest data storage costs.
- Data in warm storage comes with a lower storage cost and higher retrieval latency compared to data in hot storage.
- Data in cold storage comes with very low data storage costs, but queries on this data can take between minutes and hours to complete.
Tiered storage is ultimately a trade-off between the cost of storing data and the availability of data to support analytical use cases. Instead of sacrificing data availability for lower costs, we recommend alternative cost optimization strategies like efficient formatting and data compression to minimize storage costs while preserving the availability of data for querying.
5. Enable Multi-Model Analytics
Enabling multi-model data analytics with diverse querying capabilities gives data science and security teams, as well as non-technical users the flexibility to explore data in new ways and unlock the full value of security log data in the lakehouse.
Organizations that index data in a Databricks lakehouse using ChaosSearch gain access to true multi-model analytics capabilities, with support for:
- SQL/relational querying on structured (tabular) security data to support use cases like user authentication monitoring, behavior analytics, and incident correlation.
- Full-text search queries on unstructured security data to support use cases like forensic investigations and APT hunting.
- Gen-AI queries that make it easier for non-technical users to query security data using natural language.
Databricks users can also leverage Mosaic AI to build and deploy artificial intelligence (AI) or machine learning (ML) systems using security log data in the lakehouse.
ChaosSearch Brings Security Log Analytics Use Cases to the Databricks Lakehouse
ChaosSearch is now a Databricks technology partner, running inside the Databricks Data Intelligence Platform with native support for Delta Lake and Spark and enabling centralized log and event analytics for security operations and threat hunting use cases.
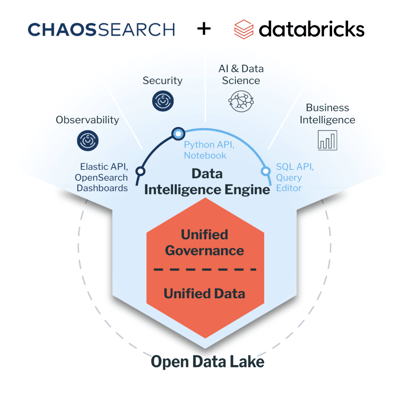
ChaosSearch provides technical solutions for many of the data retention challenges that Databricks users face when it comes to supporting long-term SecOps use cases. With ChaosSearch, Databricks users can:
- Streamline data ingestion with a schema-on-read to rapidly centralize data without the need to manage complex ETL pipelines at scale.
- Reduce data storage costs and avoid cost/availability trade-offs with proprietary data indexing and compression capabilities.
- Enable multi-model data analytics with support for SQL, full-text search, and Gen-AI querying (alongside the AI/ML capabilities of Databricks).
- Democratize data access by allowing users to interface with data using familiar tools through built-in OpenSearch Dashboards and Elastic API.
Ready to learn more?
Read the solution brief Extend Your Databricks with ChaosSearch to learn more about how ChaosSearch can enable powerful new security log analytics use cases inside your Databricks lakehouse with drastically reduced cost and effort.

