

On top of their industry-leading cloud infrastructure, Amazon Web Services (AWS) offers more than 15 cloud-based analytics services to satisfy a diverse range of business and IT use cases.
For AWS customers, understanding the features and benefits of all 15 AWS analytics services can be a daunting task - not to mention determining which analytics service(s) to deploy for a specific use case.
As a starting point, we recommend exploring the differences between two of Amazon’s most powerful and versatile analytics services: Amazon Redshift and Amazon Athena. Both of these AWS analytics services can be used to analyze big data at enterprise scale, but each one offers unique features and ultimately caters to a distinct set of use cases.

Keep reading for an in-depth look at the similarities and key differences between AWS Athena vs AWS Redshift, along with tips for deciding which use cases are best suited for each of these AWS analytics services.
What is AWS Redshift?
AWS Redshift is a cloud data warehouse service that can ingest structured and semi-structured data in multiple data formats, run SQL queries and open analytics on the data, and power dashboards and visualizations to enable data-driven insights.
Amazon Redshift is based on the popular open-source PostgreSQL database application, but was designed to deliver more scalability and cost-efficiency than a self-hosted PostgreSQL instance by leveraging cloud data storage and compute resources.
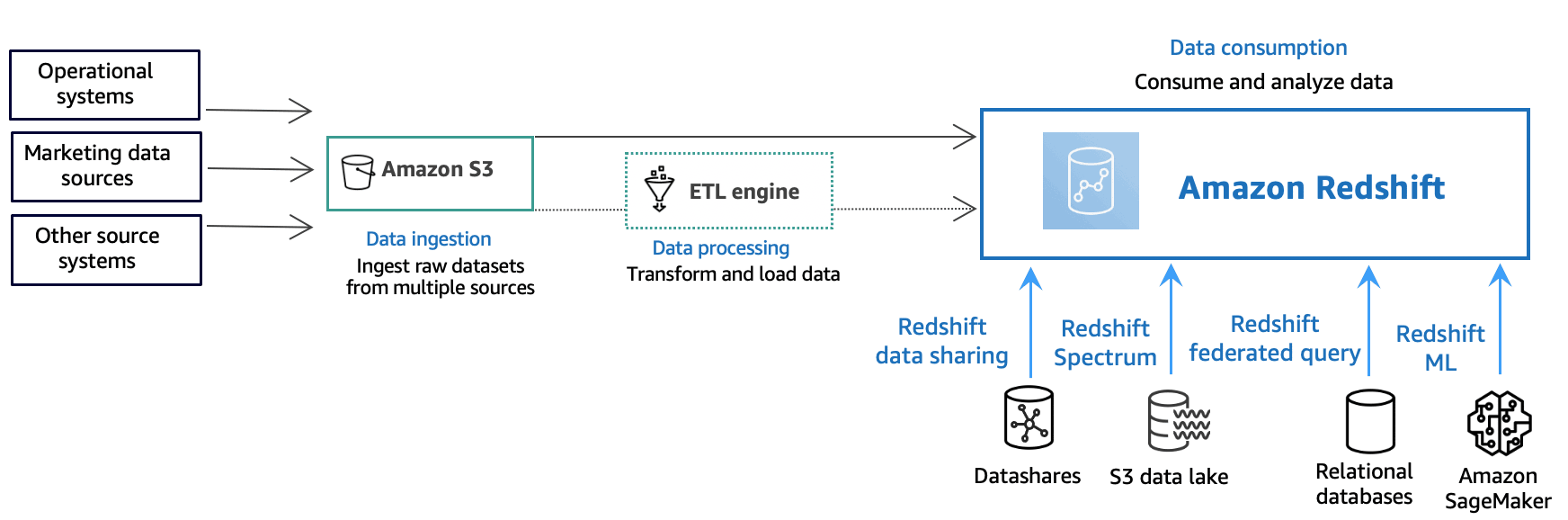
A typical data processing flow in Amazon Redshift
Redshift is delivered by AWS as a fully managed data warehouse service. AWS customers can start using Redshift by provisioning one or more Amazon Redshift clusters. There’s also a serverless deployment option that can help AWS customers get insights from data without having to provision and manage data warehouse infrastructure.
Each Redshift cluster consists of one or more compute nodes hosting a query engine and one or more databases. Redshift query engines can be orchestrated to run queries on specific databases or across multiple clusters at once. An ETL engine like AWS Glue might be used for loading the data from a variety of data sources (e.g. streaming data, databases, data lakes, etc.) into Redshift clusters.

What is AWS Athena?
AWS Athena is a cloud-based data analytics service that lets you run interactive queries against data stored in S3, the AWS object storage service. This means that Athena, which is based on the open source Presto analytics engine, can query any type of data that exists in S3 buckets, even if the data is unstructured. AWS calls Athena a serverless service because it requires no infrastructure set up or management on the part of users.
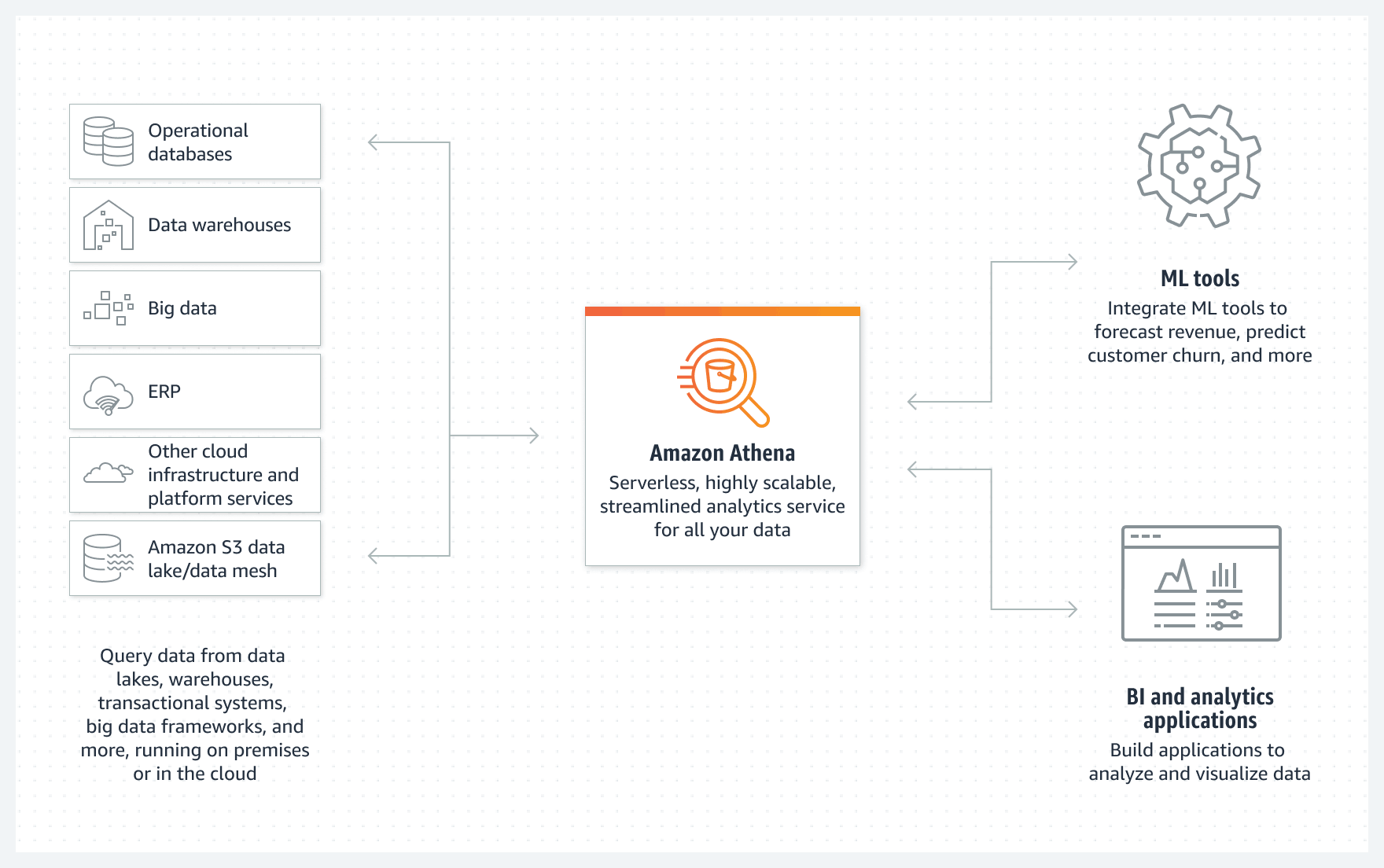
Amazon Athena enables scalable analytics on a variety of cloud and on-prem data sources
It's worth noting that Athena only supports SQL-style access to S3 data, and it doesn't provide any type of visualization or interpretation tools. Thus, Athena isn't a replacement for something like Elasticsearch. But it is useful if you are searching for specific types of data stored in S3, and you can write SQL queries for an SQL analysis that will find that data.
Main Differences between Redshift and Athena
Although Redshift and Athena both provide capabilities for analyzing data at scale, they work in different ways. The key distinctions between Redshift and Athena include:
- Data structure: Because Redshift requires you to organize data into data sets within clusters, it works best for data that is structured. In contrast, Athena can analyze raw, unstructured data spread across S3.
- Data location: Redshift requires the data that you want to analyze to be stored inside Redshift clusters. So, if you want to analyze data, you need to move it into Redshift first. Athena is different because it can analyze data that exists in S3, without any data movement required.
- Set up time: With Redshift, you need to wait for your clusters to initialize before you can begin running queries. This can take a significant amount of time. But with Athena, there is no waiting, because you don't have to move or initialize any data. You can just start running queries.
- Partitioning: Redshift and Athena both provide partitioning functionality (which speed up queries by limiting the amount of data that each query scans), but in different ways. Athena partitioning is more flexible and open-ended because you can define partitions based on any key. This means that it's easier to achieve high performance in Athena by optimizing partitioning.
- Pricing and cost: Although it's not necessarily the case that Athena costs less than Redshift, Athena pricing is simpler because you pay a flat fee (currently, $5 per terabyte) based on the amount of data you scan. Redshift pricing varies depending on cluster configuration, hourly run time and other factors, making it more difficult to know ahead of time what your ultimate cost will be.
Overall it's fair to say that Athena is more flexible – and, in certain ways, simpler – than Redshift. However, Redshift is more structured and deliberate in the way it handles data queries.
Example Use Cases for Redshift vs. Athena
Another way to think about the differences between Redshift and Athena is to focus on the varying use cases that each service lends itself to.
Examples of use cases that are a good fit for Redshift include:
- Event log analytics: Cloud application and event logs are an example of structured, consistent data that is easy to analyze within Redshift clusters.
- Real-time analytics: AWS Redshift can be integrated with data stream processing services like Amazon Kinesis to enable near real-time analysis of large-scale data streams.
- Business intelligence: AWS Redshift is a good solution if you need to store and analyze specific types of business data, including financial reports, marketing/sales data, and customer information. Since this data is relatively structured, you can fit it into Redshift clusters without difficulty.
Read: How to discover advanced persistent threats in AWS
In contrast, common Athena use cases include:
- Querying cloud service logs: Amazon CloudWatch is a service that enables cloud observability by collecting and visualizing log data from other cloud services, resources, and applications deployed on AWS. Amazon CloudWatch logs can be stored in Amazon S3 buckets, making it possible for you to run queries on the log data with Amazon Athena and achieve better CloudWatch log insights.
- Performance troubleshooting: Since Athena lets you execute ad-hoc queries quickly and without having to prepare any data, it's handy in situations where you need to query a log file or stored inside S3 on a one-off basis – as opposed to performing systematic log analytics, in which case Redshift may be a better fit.
- Querying an S3 security data lake: You can build a security data lake in the cloud by ingesting security logs into Amazon S3 and indexing them for searchability and long-term storage. Amazon Athena lets you run ad-hoc queries on your security data lake to support security operations and threat hunting use cases.
- Exploring S3 data: Athena can come in handy if you have large amounts of data inside S3 buckets and aren't sure exactly what that data is or how it's organized. By running Athena queries, you can gain visibility into your S3 data.
Read: AWS ELB Log Analysis on S3: Immediate Insights
Enable AWS Cloud-based Analytics at Scale with Chaos LakeDB
AWS Redshift and AWS Athena are versatile and feature-rich analytics services that lend themselves to similar, but distinct, use cases. Knowing which one to use is a key step in optimizing your approach to data analytics.

An alternative to AWS Redshift and AWS Athena is Chaos LakeDB, the first and only data lake database that powers full-text search, SQL and Gen AI analytics with no data movement or ETL process.
Our Redshift vs. ChaosSearch performance comparison proved that our proprietary data indexing technology offers better compression ratios than Amazon Redshift, resulting in lower data storage costs and eliminating restrictive data retention trade-offs for our customers.
Ready to learn more?
Download the Chaos LakeDB product white paper to learn more about the cutting-edge database innovations that power this innovative ChaosSearch service.
Frequently asked questions
Which software are Redshift and Athena based on?
Redshift is based on PostgreSQL, an open source database. Athena is based on Presto, an open source analytics engine.
Is Athena cheaper than Redshift?
The cost of Athena depends on how much data you scan. Redshift pricing is based on your cluster configuration and how much time your cluster operates. Athena pricing is simpler and easier to predict, but not necessarily lower.
Can Redshift analyze S3 data?
Yes, but you need to initialize a Redshift cluster first, which takes time.
Are Redshift and Athena open source?
No; they are both proprietary services developed by Amazon. However, both services are based on open source software.
Additional Resources
An Overview of Streaming Analytics in AWS for Logging Applications
Optimize Your AWS Data Lake with Data Enrichment and Smart Pipelines
10 Essential Cloud DevOps Tools for AWS
5 AWS Logging Tips and Best Practices
The Basics of Using AWS EventBridge for Observability

